SMS Text Classifier
Intro
This is the fifth project in the freeCodeCamp Machine Learning with Python Certification. For this project we have to create a machine learning model that classifies a text message as ham (normal message) or spam. We have to build a neural network with Tensorflow. We will use the boilerplate code provided by freeCodeCamp. Read more about it in Neural Network SMS Text Classifier.
Check out the full code for this project at https://colab.research.google.com/drive/1suzdQ37KgFOZ71l_yo3bpW-N-8T8f3Bu?usp=sharing
Planning
We are going to build a neural network for this project. Our data is in textual format. Before being able to use the data for training, we will need to convert it into the right format. We can clean the text data by making it all lowercase and removing punctuations, formatting, numbers, etc. We can then create a “bag of words” or “vocabulary” from the training dataset and use it to map the text data to integer vectors. Since the text messages are of different lengths, the integer vectors will be of different sizes and the order of words will be different too. We will need to create embeddings of same size for all the vectors.
We also don’t want to manually do these steps every time we want to classify a new text message. We can offload these tasks to layers in our model. The first two layers in our model can be for vectorizing and embedding the data.
The next few layers would be regular neural network layers and the output layer will give up a probability of the message being ham or spam.
Code
Fetch the dataset by running in shell
wget https://cdn.freecodecamp.org/project-data/sms/train-data.tsv
wget https://cdn.freecodecamp.org/project-data/sms/valid-data.tsvImport some libraries in our python code
import numpy as np
import pandas as pd
import tensorflow as tf
from tensorflow import keras
import matplotlib.pyplot as pltData
Load the training and validation datasets to DataFrames
train_file_path = "train-data.tsv"
test_file_path = "valid-data.tsv"
train_dataset = pd.read_csv(train_file_path, delimiter='\t', header=None, names=['label', 'message'])
valid_dataset = pd.read_csv(test_file_path, delimiter='\t', header=None, names=['label', 'message'])Check if our data is imported correctly
train_dataset.head()| label | message | |
|---|---|---|
| 0 | ham | ahhhh…just woken up!had a bad dream about u … |
| 1 | ham | you can never do nothing |
| 2 | ham | now u sound like manky scouse boy steve,like! … |
| 3 | ham | mum say we wan to go then go… then she can s… |
| 4 | ham | never y lei… i v lazy… got wat? dat day ü … |
valid_dataset.head()| label | message | |
|---|---|---|
| 0 | ham | i am in hospital da. . i will return home in e… |
| 1 | ham | not much, just some textin’. how bout you? |
| 2 | ham | i probably won’t eat at all today. i think i’m… |
| 3 | ham | don‘t give a flying monkeys wot they think and… |
| 4 | ham | who are you seeing? |
Pop off the label column to generate labels for training and validation
train_labels = train_dataset.pop('label')
valid_labels = valid_dataset.pop('label')The labels are “ham” and “spam”. We will need numerical values instead of string to train our model. We can factorize the training labels
train_labels, label_index = train_labels.factorize()
train_labels
array([0, 0, 0, ..., 1, 1, 0])Check our label to int mapping
label_dict = {label:idx for idx, label in enumerate(label_index)}
label_dict
{'ham': 0, 'spam': 1}We will also need to factorize the validation set with the same indices
valid_labels = np.array(valid_labels.apply(lambda label: label_dict[label]))
valid_labels
```samp
array([0, 0, 0, ..., 0, 1, 1])
```Model
We will create our neural network using Keras sequential model
model = keras.models.Sequential()Our first layer should take in the SMS text as input and convert it into list of token indices (vectorize). This layer is also going to standardize the text input.
Let’s create a function to standardize to pass to our first layer . We will convert everything to lower case and remove everything other than alphabets
def sms_standardize(input):
retVal = tf.strings.lower(input)
retVal = tf.strings.regex_replace(retVal, '[^a-z]', ' ')
return retValCreate the vectorize layer and pass in the function
vectorize_layer = tf.keras.layers.TextVectorization(standardize=sms_standardize)Call the adapt method on the layer with the tokenized train dataset to compute the vocabulary
vectorize_layer.adapt(train_dataset.message.to_numpy())vocab_size = vectorize_layer.vocabulary_size()
vocab_size
6684Add this layer to the model
model.add(vectorize_layer)Add an Embedding layer to convert the token indices from previous layer to fixed size embedding
embedding_dim=32
model.add(keras.layers.Embedding(vocab_size, embedding_dim))Now we can add some generic layers like Pooling, Dense and Dropout
model.add(keras.layers.Dropout(0.2))
model.add(keras.layers.Dense(2))
model.add(keras.layers.Dropout(0.2))For the final layer, add a Dense layer with one unit and sigmoid activation. Sigmoid activation gives us an output in the range [0, 1]. This would be the probability of a text message being “spam” since the labels were zero for ham and one for spam
model.add(keras.layers.Dense(1, activation="sigmoid"))Check the model summary
model.summary()
Model: "sequential_17"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
text_vectorization (TextVe (None, None) 0
ctorization)
embedding_17 (Embedding) (None, None, 32) 213888
global_average_pooling1d_1 (None, 32) 0
7 (GlobalAveragePooling1D)
dropout_18 (Dropout) (None, 32) 0
dense_34 (Dense) (None, 2) 66
dropout_19 (Dropout) (None, 2) 0
dense_35 (Dense) (None, 1) 3
=================================================================
Total params: 213957 (835.77 KB)
Trainable params: 213957 (835.77 KB)
Non-trainable params: 0 (0.00 Byte)
_________________________________________________________________Compile the model. We will use binary crossentropy for loss function since we only have two labels and this is a classification model
model.compile(
optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy']
)Training
Train the model for 25 epochs by calling the fit method
history = model.fit(
x=train_dataset,
y=train_labels,
validation_data=(valid_dataset, valid_labels),
epochs=25
)
Epoch 1/25
131/131 [==============================] - 2s 8ms/step - loss: 0.4912 - accuracy: 0.8397 - val_loss: 0.3271 - val_accuracy: 0.8657
Epoch 2/25
131/131 [==============================] - 1s 6ms/step - loss: 0.3126 - accuracy: 0.8744 - val_loss: 0.2568 - val_accuracy: 0.8858
Epoch 3/25
131/131 [==============================] - 1s 7ms/step - loss: 0.2583 - accuracy: 0.9069 - val_loss: 0.1951 - val_accuracy: 0.9167
...
Epoch 23/25
131/131 [==============================] - 1s 9ms/step - loss: 0.0341 - accuracy: 0.9921 - val_loss: 0.0383 - val_accuracy: 0.9878
Epoch 24/25
131/131 [==============================] - 1s 9ms/step - loss: 0.0329 - accuracy: 0.9904 - val_loss: 0.0377 - val_accuracy: 0.9907
Epoch 25/25
131/131 [==============================] - 1s 7ms/step - loss: 0.0317 - accuracy: 0.9907 - val_loss: 0.0381 - val_accuracy: 0.9885Take a look at the training loss history
fig, axes = plt.subplots(figsize=(5,3))
axes.plot(history.history['loss'])
axes.plot(history.history['val_loss'])
axes.set_xlabel('Epochs')
axes.set_ylabel('Loss')
axes.legend(['Loss', 'Validation Loss'])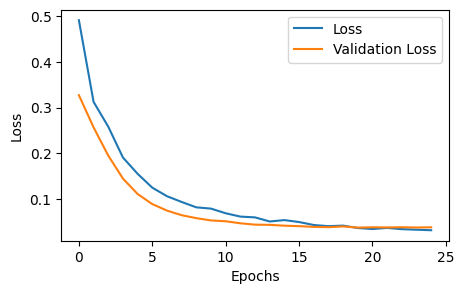
Testing
Create a function to get the predictions
def predict_message(pred_text):
result = model.predict([pred_text])
return ([result, 'ham' if result<0.5 else 'spam'])Test the prediction function
pred_text = "how are you doing today?"
prediction = predict_message(pred_text)
print(prediction)
1/1 [==============================] - 0s 133ms/step
[array([[6.8955176e-12]], dtype=float32), 'ham']This message was correctly identified. Let’s run the freeCodeCamp test to check if the model passes
# Run this cell to test your function and model. Do not modify contents.
def test_predictions():
test_messages = ["how are you doing today",
"sale today! to stop texts call 98912460324",
"i dont want to go. can we try it a different day? available sat",
"our new mobile video service is live. just install on your phone to start watching.",
"you have won £1000 cash! call to claim your prize.",
"i'll bring it tomorrow. don't forget the milk.",
"wow, is your arm alright. that happened to me one time too"
]
test_answers = ["ham", "spam", "ham", "spam", "spam", "ham", "ham"]
passed = True
for msg, ans in zip(test_messages, test_answers):
prediction = predict_message(msg)
if prediction[1] != ans:
passed = False
if passed:
print("You passed the challenge. Great job!")
else:
print("You haven't passed yet. Keep trying.")
test_predictions()
1/1 [==============================] - 0s 39ms/step
1/1 [==============================] - 0s 42ms/step
1/1 [==============================] - 0s 40ms/step
1/1 [==============================] - 0s 42ms/step
1/1 [==============================] - 0s 33ms/step
1/1 [==============================] - 0s 33ms/step
1/1 [==============================] - 0s 42ms/step
You passed the challenge. Great job!The model correctly classifies the messages as ham or spam!
Thank you for reading. You can also check out my other projects for this series below.