Cat and Dog Image Classifier
Intro
This is the second project in the freeCodeCamp Machine Learning with Python Certification. For this project we have to train a model to classify images of cat and dog. We have to use Tensorflow and Keras to build and train the model. We will use the boilerplate code provided by freeCodeCamp. The Read more about it in Cat and Dog Image Classifier.
Check out the full code for this project at https://colab.research.google.com/drive/1DXn69rRapXq7gEivdzXuF6vsOkPz8j3_?usp=sharing
Planning
The images for training, validation and testing are already separated in different directories. The training and validation images are further divided into subdirectories “cat” and “dog”. We can use Tensorflow’s image generator to fetch images and preprocess them.
We will use convolutional neural network since they work well for image classification tasks. The convolutional layers are good for feature extraction from two dimensional data where each data point could be related to the other points close to it. We will have a few convolutional layers, followed by a few normal layers, which will use the extracted features and generate a classification.
We can then train our model with the training set and make predictions on the test set.
Code
I will put a note before the code blocks provided by freeCodeCamp and briefly go over them, so we can follow what is happening in the program.
Setup
First step is to import the libraries we are going to use: Tensorflow, Keras (models, layers, preprocessing), Numpy and Matplotlib.
NOTE: This code block is provided by freeCodeCamp
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Conv2D, Flatten, Dropout, MaxPooling2D
from tensorflow.keras.preprocessing.image import ImageDataGenerator
import os
import numpy as np
import matplotlib.pyplot as pltGet the zip containing images and unzip. For use in colaboratory notebooks, add an exclamation mark (!) before the shell commands
NOTE: This code block is provided by freeCodeCamp
$ wget https://cdn.freecodecamp.org/project-data/cats-and-dogs/cats_and_dogs.zip
$ unzip cats_and_dogs.zipSave the directory locations for training, testing and validation for future use.
NOTE: This code block is provided by freeCodeCamp
PATH = 'cats_and_dogs'
train_dir = os.path.join(PATH, 'train')
validation_dir = os.path.join(PATH, 'validation')
test_dir = os.path.join(PATH, 'test')Get the number of files in each directory
NOTE: This code block is provided by freeCodeCamp
total_train = sum([len(files) for r, d, files in os.walk(train_dir)])
total_val = sum([len(files) for r, d, files in os.walk(validation_dir)])
total_test = len(os.listdir(test_dir))Define some parameters to be used by preprocessing and training. We can change the batch_size and epochs later.
NOTE: This code block is provided by freeCodeCamp
batch_size = 128
epochs = 15
IMG_HEIGHT = 150
IMG_WIDTH = 150We also have a function for plotting images and the predictions if they are passed in to the optional parameter.
NOTE: This code block is provided by freeCodeCamp
def plotImages(images_arr, probabilities = False):
fig, axes = plt.subplots(len(images_arr), 1, figsize=(5,len(images_arr) * 3))
if probabilities is False:
for img, ax in zip( images_arr, axes):
ax.imshow(img)
ax.axis('off')
else:
for img, probability, ax in zip( images_arr, probabilities, axes):
ax.imshow(img)
ax.axis('off')
if probability > 0.5:
ax.set_title("%.2f" % (probability*100) + "% dog")
else:
ax.set_title("%.2f" % ((1-probability)*100) + "% cat")
plt.show()Data generators
Since we have a small number of images, we will use Tensorflow’s image data generators to create multiple training images from each image in the training folder by applying transformations of our choice. We will also use the data generators to pipe the images for training, validation and testing.
Let’s start with training images. We will normalize them using rescale param. Since the color values are between 0 and 255, we can use 1.0/255 to get a range between 0 and 1. We will also apply transformation like rotation, shifting zoom and brightness. Most of the arguments are self explanatory
train_image_generator = ImageDataGenerator(
rescale=1.0/255,
rotation_range=90,
horizontal_flip=True, vertical_flip=False,
width_shift_range=0.2, height_shift_range=0.2,
zoom_range=0.15,
brightness_range=(0.3,1.0)
)The validation and testing generators are simpler since we don’t need to create more data. We just need to normalize the values
validation_image_generator = ImageDataGenerator(rescale=1.0/255)
test_image_generator = ImageDataGenerator(rescale=1.0/255)Now we can use these generators to generate batches of data using our directories. We will use the image generator’s from_from_directory method which will return a directory iterator for images and their labels.
The training data and validation data directory iterators will look quite similar. We pass in the directory, the target size, batch size and class mode. The “binary” class mode will produce 1D binary labels (0 and 1). The classes are automatically inferred from the subdirectory names, “cats” and “dogs” in our case
train_data_gen = train_image_generator.flow_from_directory(
train_dir, target_size=(IMG_HEIGHT, IMG_WIDTH),
batch_size=batch_size, class_mode='binary'
)
val_data_gen = validation_image_generator.flow_from_directory(
validation_dir, target_size=(IMG_HEIGHT, IMG_WIDTH),
batch_size=batch_size, class_mode='binary'
)The testing data directory iterator will be a bit different. We will use empty string for class names, since the image are not categorized and are not inside subdirectories. We will also set shuffle to False so we can relate the predictions to the original images.
test_data_gen = test_image_generator.flow_from_directory(
test_dir, target_size=(IMG_HEIGHT, IMG_WIDTH),
classes=[''],
batch_size=batch_size, class_mode=None,
shuffle=False,
)Model
We are going to build a convolutional neural network for this project. We can use Keras API from Tensorflow library and use the Sequential model
model = Sequential()Add the input layer with the shape of our images. We have 150 height, 150 width and 3 depth (RGB)
model.add(Input(shape=(150,150,3)))Next we can build a network of layers. We can extract features from the images using Conv2D layers.
Add a Conv2D layer with 64 filters, 2x2 convolutional window and 1x1 step size for the window. We will pick relu as the activation function
model.add(Conv2D(64, (2,2), strides=(1,1), padding="same", activation="relu"))Add a Dropout layer to prevent overfitting
model.add(Dropout(0.2))We can add a few more Conv2D and Dropout layers. We can also pick different arguments for them
model.add(Conv2D(64, (2,2), strides=(1,1), padding="same", activation="relu"))
model.add(Dropout(0.2))
model.add(Conv2D(32, (2,2), strides=(1,1), padding="same", activation="relu"))Add a MaxPooling2D layer to downsample the kernels generated from the previous layers. MaxPooling2D outputs the maximum value in the window. We will keep the default window size of 2x2
model.add(MaxPooling2D())Add a Flatten layer to convert the 2D output of the previous layer to 1D
model.add(Flatten())Add a couple of Dense layers to create regular neural network layers. The activation function for the last layer should output either 0 or 1 for binary classification. It can also output values in the range [0,1] as a probability for the classification. We will use sigmoid to get probabilities
model.add(Dense(256, activation="relu"))
model.add(Dense(128, activation="relu"))
model.add(Dense(1, activation="sigmoid"))With this our model is complete. We can now compile the model. We will use the Adam optimizer, binary cross entropy as the loss function since we have binary labels and accuracy as the metric
model.compile(optimizer=tf.optimizers.Adam(learning_rate=0.0005),
loss='binary_crossentropy', metrics=['accuracy'])We can get a nice view of all the layers, input and outputs of the layers with model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 150, 150, 64) 832
dropout (Dropout) (None, 150, 150, 64) 0
conv2d_1 (Conv2D) (None, 150, 150, 64) 16448
dropout_1 (Dropout) (None, 150, 150, 64) 0
conv2d_2 (Conv2D) (None, 150, 150, 32) 8224
max_pooling2d (MaxPooling2 (None, 75, 75, 32) 0
D)
flatten (Flatten) (None, 180000) 0
dense (Dense) (None, 256) 46080256
dense_1 (Dense) (None, 128) 32896
dense_2 (Dense) (None, 1) 129
=================================================================
Total params: 46138785 (176.01 MB)
Trainable params: 46138785 (176.01 MB)
Non-trainable params: 0 (0.00 Byte)
_________________________________________________________________Training
We can begin training the model. We need to call model.fit with the params. We will pass in the training and validation data iterators we created above. We will also store the output which includes the training and validation loss and metrics at each epoch
history = model.fit(x=train_data_gen,
batch_size=batch_size,
epochs=epochs, steps_per_epoch=None,
validation_data=val_data_gen, validation_steps=None
)Output of training the model with the fit function
Epoch 1/15
16/16 [==============================] - 40s 1s/step - loss: 1.3130 - accuracy: 0.5020 - val_loss: 0.6920 - val_accuracy: 0.5000
Epoch 2/15
16/16 [==============================] - 19s 1s/step - loss: 0.6981 - accuracy: 0.4905 - val_loss: 0.6924 - val_accuracy: 0.5280
Epoch 3/15
16/16 [==============================] - 19s 1s/step - loss: 0.6945 - accuracy: 0.4965 - val_loss: 0.6929 - val_accuracy: 0.5070
Epoch 4/15
16/16 [==============================] - 20s 1s/step - loss: 0.6926 - accuracy: 0.5325 - val_loss: 0.6926 - val_accuracy: 0.5650
Epoch 5/15
16/16 [==============================] - 19s 1s/step - loss: 0.6898 - accuracy: 0.5325 - val_loss: 0.6911 - val_accuracy: 0.5850
Epoch 6/15
16/16 [==============================] - 20s 1s/step - loss: 0.6838 - accuracy: 0.5455 - val_loss: 0.6852 - val_accuracy: 0.5800
Epoch 7/15
16/16 [==============================] - 20s 1s/step - loss: 0.6715 - accuracy: 0.5785 - val_loss: 0.6766 - val_accuracy: 0.5700
Epoch 8/15
16/16 [==============================] - 19s 1s/step - loss: 0.6679 - accuracy: 0.5730 - val_loss: 0.6709 - val_accuracy: 0.5950
Epoch 9/15
16/16 [==============================] - 20s 1s/step - loss: 0.6578 - accuracy: 0.6000 - val_loss: 0.6629 - val_accuracy: 0.6070
Epoch 10/15
16/16 [==============================] - 19s 1s/step - loss: 0.6455 - accuracy: 0.6135 - val_loss: 0.6508 - val_accuracy: 0.6080
Epoch 11/15
16/16 [==============================] - 20s 1s/step - loss: 0.6447 - accuracy: 0.6120 - val_loss: 0.6622 - val_accuracy: 0.6240
Epoch 12/15
16/16 [==============================] - 20s 1s/step - loss: 0.6387 - accuracy: 0.6300 - val_loss: 0.6486 - val_accuracy: 0.6160
Epoch 13/15
16/16 [==============================] - 19s 1s/step - loss: 0.6351 - accuracy: 0.6385 - val_loss: 0.6454 - val_accuracy: 0.6410
Epoch 14/15
16/16 [==============================] - 20s 1s/step - loss: 0.6396 - accuracy: 0.6070 - val_loss: 0.6541 - val_accuracy: 0.6190
Epoch 15/15
16/16 [==============================] - 19s 1s/step - loss: 0.6358 - accuracy: 0.6305 - val_loss: 0.6472 - val_accuracy: 0.6320We can graph the training and validation loss and accuracy. We can see the training and validation loss decreasing and the accuracy increasing
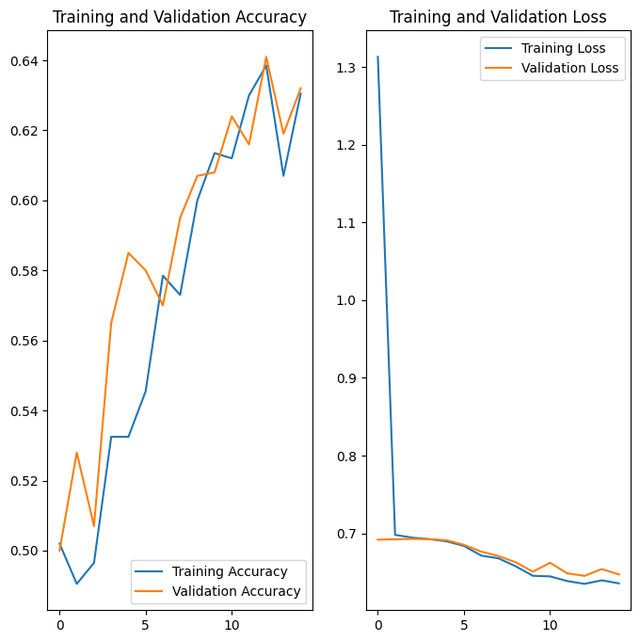
Testing
We trained our model in the last section. Now it’s time to use it to generate predictions on our test data. We can use the model.predict function and pass in the test data iterator
predictions = list(model.predict(test_data_gen, batch_size=batch_size))
probabilities = [float(pred) for pred in predictions]We can use the plotImages function provided by freeCodeCamp to plot images and their predictions. Check those out using the colab notebook link in the intro section.
We have passed the freeCodeCamp challenge requirement and have about 68% accuracy with the model trained under half a minute!
Your model correctly identified 68.0% of the images of cats and dogs.
You passed the challenge!Thank you for reading. You can also check out my other projects for this series below.